
This article is a joint compilation: Blake, Gao Fei
Lei Fengnet Note: Geoffrey Everest Hinton (Jeffrey Everest Hinton) is a British-born computer scientist and psychologist, known for his contributions to the neural network. Hinton is one of the inventors of the back propagation algorithm and the contrast divergence algorithm, and an active promoter of deep learning. He is currently with the University of Toronto and Google. As one of the three founders in the field of artificial intelligence, as early as 30 years ago, Hinton has left his mark in deep learning. However, until the computer's performance reached the requirements of deep learning, Xin Ting began to gain wide recognition outside of academia. This article is his presentation PPT for deep learning.


Deep learning
Geoffrey Hinton
University of Toronto & Google

Spectrum of machine learning tasks
Typical statistical methods
Low-dimensional data (for example, less than 1000 dimensions)
There is a lot of noise in the data
The data does not have a sound structure, how a minimal model represents the data structure
The main problem is to distinguish between real structure and data noise     Â
Artificial Intelligence (AI)
High-dimensional data (for example, more than 1000 dimensions)
If noise is properly handled, the noise is not sufficient to obscure the internal structure of the data.
There is a huge structure in the data, and the data structure is too complex to represent with a simple model.
The main problem is to figure out how to represent complex data structures, making this structure easy to learn

A brief history of deep learning
The back-propagation algorithm used to learn multilayer nonlinear features was proposed in the 1970s and 1980s and has evolved several times (Werbos, Amari, Parker, Lecun, Rumelhart et al.).
At the time, the back propagation algorithm had a broad application prospect. However, by the 1990s, many researchers in the field of machine learning began to stop using this algorithm for the following reasons:
- The algorithm cannot effectively use most hidden layers (except its application in "delay" and convolutional networks).
- The algorithm cannot play an effective role in recursive networks.

How to learn multi-layer features (~1985)
Use the backpropagation error signal to obtain derivative tools for learning:
First input the input information vector, through the hidden layer, and finally get the output result, and compare the output result with the correct answer to get the error signal.

Stochastic gradient descent
Calculate the gradient vector of ownership weights for a small number of random "small batches" of training data.
- This will randomly evaluate the gradient vectors of all training data.
- If the weight value is completely wrong, even if it is costly, it is meaningless to accurately estimate the value.
Reduce the gradient estimate slightly to update the weight of the ownership.
- Compared to other better methods, this original optimization method can play a better role in large data sets.

What is wrong with the back propagation algorithm? - Perspectives of the 1990s
The back propagation algorithm requires a large amount of marked training data
— Almost all data is unmarked.
Back propagation algorithm fails to plan learning time
— In networks with many hidden layers, the algorithm is very slow to learn.
In the local optimization process, back propagation algorithm will appear stuck phenomenon
— The algorithm can usually be used very well, but it has never been an excellent theory.

Using unsupervised learning methods to overcome the limitations of back propagation algorithms
Maintain the effectiveness and simplicity of the gradient method to adjust the weight value, and use this method to construct the structure for sensory input information.
- Adjust the weights to ensure that a generated model generates the maximum likelihood of sensory input.
— Learn images instead of marked images.
If you want to do research in the field of computer vision, you are most likely to learn computer graphics.
Which generative model should we learn?

Random Binary Unit (An Odd Choice Method)
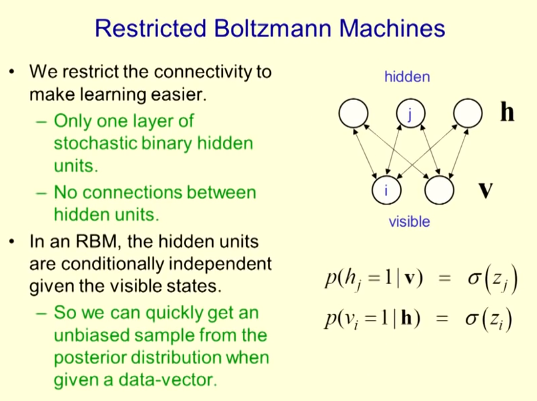
Restricted Boltzmann Machine
Limit the connectivity between layers and make learning easier.
- There is only one layer of random binary hidden units.
- No connection between hidden layers.
In the restricted Boltzmann machine, there is a conditional independent relationship between hidden layers in view of the visual state.
— When there is an established data vector, we can quickly obtain an unbiased sample from the posterior distribution.
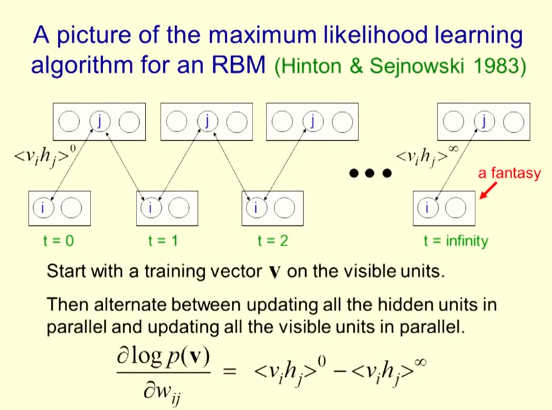
Restricted Boltzmann Machine Maximum Likelihood Learning Algorithm
It starts with a training vector V of the visual unit.
Updates between updating all parallel hidden units and updating all parallel visible units.

Fast learning method of restricted Boltzmann machine
The beginning of a training vector by the visual unit
Update all parallel hidden units
Update all parallel visual units for refactoring
Update hidden units again

Narration
Netflix can predict how much you like a movie by averaging the predicted values ​​obtained using two different methods.
One of these methods uses a restricted Boltzmann machine trained on an algorithm version of a fast approximation learning algorithm.
This is the first major application of a restricted Boltzmann machine.

Training Depth Network (The main reason for the limited popularity of Boltzmann machines is the support of the Gatsby Fund)
First, the feature layer that directly obtains the input information from the pixels is trained.
Next, these trained characteristics are treated as pixels, these features are activated, and the features of these features are learned in the second hidden layer.
This generates a multi-layer production model.
Whenever we add a feature layer, we can get a better lower bound on the logarithmic probability of training data, which can be confirmed.
This process of proof is very complicated (but it is extremely important for mutual respect among academic colleagues).

Fine adjustments to achieve this purpose
Pre-training: First, only one feature layer is learned at a time, and marked information is not used.
Fine-tuning: Adding the last marker unit layer, reverses the error of the marker unit to fine-tune the features learned during the unsupervised early training phase.
This fine-tuning method can overcome two major limitations of the standard back-propagation algorithm.
Because we found good features without tagging data, we require fewer tags.
As the pre-training process only trains one layer at a time and is finely tuned from perceivable features, the learning speed becomes faster and faster.

Constructing acoustic models for pre-training deep neural networks
After using the standard post-processing of the dual cell phone model, a 23.0% cell phone error rate was obtained.
TIMIT had previously obtained an optimal result of 24.4%, which required averaging the results of several models.
Through a short period of pre-processing, we can now do better in this piece.

What will happen next
When the performance of the pre-trained deep neural network is better than that of the Gaussian mixture model consistently advocated by the MSR lecture group, IBM and Google have further developed such deep neural networks.
Until 2012, the sound search function of Android was to use an acoustic model based on deep neural networks.
Now all leading teams use neural networks, and this technology is evolving into recursive neural networks with better and better performance.

ImageNet's ILSVRC-2012 Competition
A data set with 1.2 million high-resolution training images.
1000 different types of objects.
The task is to guess "correct" in the first five guesses.
In this data set, some existing computer vision methods are tested.
The 2012 computer vision system uses a complex multi-layer system that uses manual engineering.
The early stage is mainly adjusted by optimizing some parameters.

The error rate of ILSVRC-2012 competition
Deep Convolutional Neural Network 2015 5%
University of Toronto (Krizhevsky et al., 2012) 16%
University of Tokyo 26%
Oxford University (Zisserman et al.) 27%
INRIA (National Academy of Sciences, France) and XRCE (Xerox Research Center, Europe) 27%
University of Amsterdam 29%
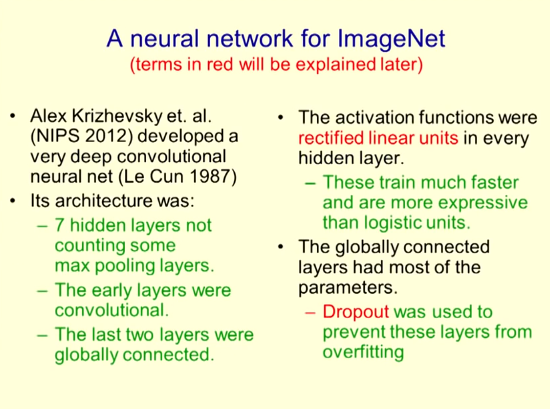
Neural Network for Imagenet
Alex Krizhevsky et al. developed a very deep convolutional neural network (Le Cunn 1987) at NIPS 2012. Its architecture includes:
l 7 hidden layers (excluding the largest pooled layer)
l Early levels are convolved
l The last two layers are globally connected
The activation function is a modified linear unit for each hidden layer
These trainings are much faster and more expressive than logical units
The global connection layer has the most parameters
Dropout is used to prevent over-fitting of these levels

Samples on the test set (and neural network guessing results)
Cheetah (Leopard Snow Leopard Egyptian Cat)
High-speed train (sedan subway tram)
Magnifier (scissors, magnifying glass, frying pan, stethoscope)
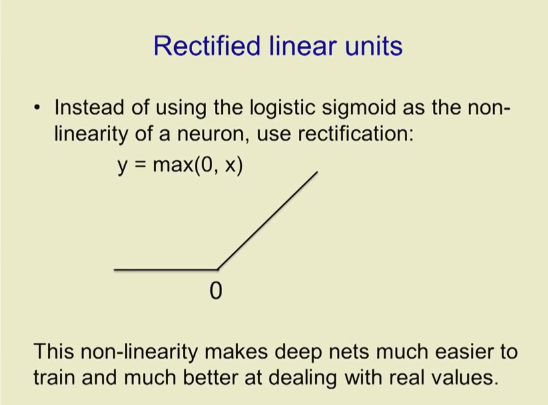
Modified linear unit
Use logical bending and nonlinear nerve correction
y = max(0,x)
This non-linearity makes the deep network easier to train and performs better when dealing with real values.
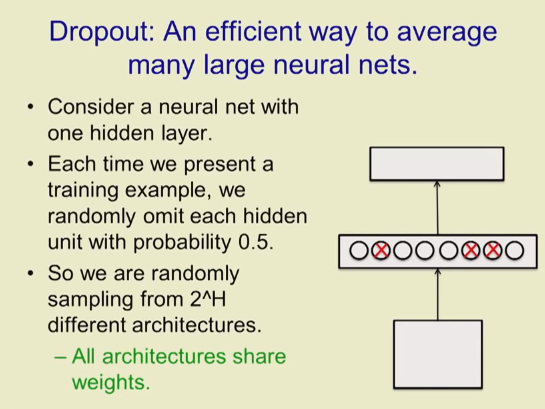
Dropout: An Effective Way to Average Multiple Large Neural Networks
Imagine a neural network that includes a hidden layer
Each time a training sample is proposed, a hidden unit is randomly omitted with a probability of 0.5
So we sample randomly from 2^H different frameworks
All architectures have the same weight

Dropout as a model average
We sample from the 2^H model. Only a few model levels have been trained and they have only trained one sample.
Weight sharing means that each of them is very regularized
This is better than trying to keep the weights in a smaller state.

What do we do during the test?
We can sample many different architectures and then take the geometric mean in their output distribution.
It is better to use all hidden units, but to halve their input weight
This happens to calculate the geometric mean of all 2^H model predictions.
In the case of more hidden layers, halving the weight during the test period is the only approximation to the average of the model, but it gives good results

What was wrong with the directional propagation algorithm proposed in 1986?
Regarding why it failed, we have come to the wrong conclusion. The real reason is:
1. Our tagged data set is too small. (several thousand times the difference)
2. Our computing power is too slow. (million times difference)
3. The way we initialize weights is wrong.
4. We used the wrong nonlinear category.
A few years ago, Jeff Dean thought that if the computing power was sufficient, the neural network might be able to do something very remarkable.
He built a number of architectures for some large neural networks to train in Google's core data center blocks.

Convolutional neural network (some complicated details have been omitted)
The best types of convolutional networks can be found in the details of articles published by Hochreiter and Schmidhuber in 1997.

Convolutional neural network
Convolutional neural networks are very powerful because they combine two features.
l Distributed hidden layers allow them to store information effectively
l Nonlinear dynamics allow them to update hidden layers in a complex way
l The deeper the depth, the better performance

A New Approach to Machine Translation (Suskever, Vinyals and Le, 2014)
For each language, we have a depth encoder RNN and a depth decoder RNN
The encoder RNN for the original language reads in the order of the text in the statement
Its final hidden layer represents the meaning of the statement.
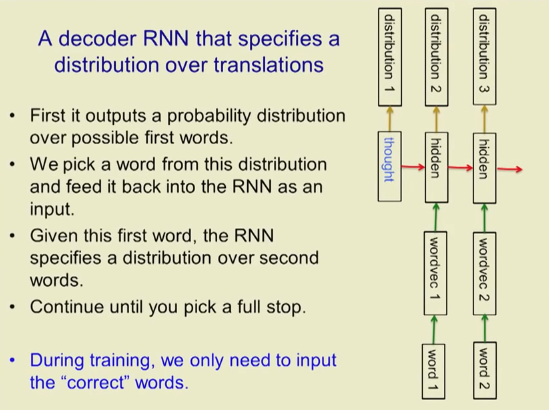
A decoder RNN for translation distribution
First it outputs the probability distribution of the first possible word
We select a word in this distribution and then feed it back to the most input in the RNN
Given the first word, RNN specifies the distribution of the second word
Continue until you finish
During training, we only need to enter the "correct" word.

How encoder and decoder networks are trained
Given a sentence pattern group, use back propagation to maximize the log likelihood of a particular translation
Currently this system only trains a group of languages
The system has achieved the best level of data on this system
It takes about a year to develop the system
If we use more data and perform training encoders and decoders simultaneously for multiple languages, it will perform much better.
The European Parliament gave us 25 ways. We can use all 25 decoders to back-propagating.

Combining vision and language (a brief introduction to recent work such as Vinyals)
In the deep convolutional network trained on the imagent, the activity vector of the last hidden layer is the “cognition†of the content in the encoded image.
Cognitive planning to the initial hidden layer of deep convolutional neural networks
Train the RNN to output what it sees in the picture
Use a dataset with 200,000 images (a few notes per image)
No longer repeat training for convolutional neural networks

A group of people shopping in an outdoor market
(People huddled around an open market)

Close-up of a child holding a stuffed animal toy
(A little girl sleeps on the sofa holding a teddy bear)

The meaning of text processing
Once we can translate a sentence into a thought vector, then a text can also become a series of thought vectors.
In the next few years, people will use deep RNNs to learn to model the idea vector sequence.
This will capture the natural reasoning process
It should allow us to understand the meaning of the text
We may need billions of neurons and billions of parameters to achieve human understanding.

The meaning of classic AI
For physicists, light waves must travel through the ether
They think there is no other possibility
For AI researchers, people must use formal rules of reasoning to spread meaning through one argument.
They think there is no other possibility
Neural network internal encoders and decoders have no symbols specifically for machine translation
The only symbols are input and output
Maybe processing symbol strings is not done by manipulating internal symbol strings
Handling pixel arrays is definitely not done by manipulating internal pixels

Where does deep learning come from?
All major ideas and almost all practical results are derived from interest-based research. (Gatsby Fund is very important)
The goal is to encourage government funding for translation studies to also contribute to the development of deep learning science and technology.
The company specializes in developing new ideas
In the long run, the idea of ​​a good idea is a real bottleneck
So give the university infrastructure to develop real ideas
PS : This article was compiled by Lei Feng Network (search "Lei Feng Network" public number attention) , refused to reprint without permission!
Via Geoffrey Hinton